Over the past year, my workflow has shifted from mostly chat-based AI assistance to long-running agents that prototype entire ideas for me. As agents got better at completing larger projects autonomously, I wrote more ambitious specs and let the agents complete more tasks on their own. But this meant reviewing more and more code to determine whether the agent had actually built what I wanted. For simple features, I could just run it and check it visually, but the harder ones pulled me into a strange loop where verifying the agent’s work required me to already understand the code well enough to know where to look.
The more I thought about it, the more I realized I was approaching this from the wrong direction. Giving an agent a spec, waiting for it to finish writing the code, and then trying to verify the result as a separate step was making the task unnecessarily difficult. If I knew I was going to have to verify the result of every spec, why not integrate verification into the spec from the start? That insight eventually led me to think more deeply about which decisions I could delegate to AI and which ones I couldn’t.
The latest models can easily fix bugs in a loop until the code runs, but that doesn’t necessarily mean that the agent built what you asked it to build. Our focus needs to shift to iterating on ideas instead of iterating on code. You can go from a half-formed idea to a working prototype in an afternoon, but so can everyone else using the same models. The thing that actually makes your work stand out is the willingness to explore beyond what the models produce by default. Conventional design choices can be delegated to AI in parallel, but the choices that infuse your work with taste and innovation can’t be delegated easily. Models naturally revert to the safest, most conventional approach at every step, and those choices compound, so the quality of the work you produce depends on whether you’re engaging with the moments that actually shape the outcome rather than letting the model decide for you.
What Are Decision Points?
Decision points are the few moments in any project where your input has a larger impact on the direction of the project. A few minutes of human judgment at the right time saves hours of agent work heading in the wrong direction. Many developers may already be familiar with gates and approval processes which can serve a similar purpose in the software development lifecycle, but they often imply a sequence where nothing moves forward until someone signs off. The future of AI-assisted development is moving towards running many agents in parallel across multiple avenues of exploration and jumping in where you’re needed, which requires a less rigid approvals process and so that we’re not just minimizing risk but also maximizing exploration. I wrote about this tradeoff previously in Top-Down vs. Bottom-Up Development.
The simplest way to think about decision points is that different types of work need different amounts of human involvement, and finding the areas where your judgement is needed requires deliberate thought about your workflow. Some work is obvious enough that you can describe it and let the agent build it, because the intent is clear and the scope is well-defined. But when there’s real ambiguity about direction, sending the agent straight to implementation means it fills in every uncertain decision with its own defaults, and those defaults tend to converge on the safest, most generic options rather than the innovative ones. Brainstorming and planning address this at different levels. Brainstorming a rough idea can help by exploring the idea space first to help sharpen the intent, making sure you actually know what you want before figuring out how to build it. Planning is about exploring the design space by clarifying scope and architectural decisions, making sure the technical approach holds up before the agent starts writing code. Task decomposition helps you steer the technical implementation of complex plans. Each level gives you a chance to confirm that the right assumptions have been made before moving to the next, so that by the time the agent is implementing, the decisions it’s making on its own are the ones you’re actually comfortable delegating.
Figure-1: Each task is represented by a card on the kanban board. As the task progresses, it moves left-to-right across the columns of the board. However, depending on the type of work, a given task might skip certain columns entirely.
Choosing the right amount of specification and planning for a given idea is itself a decision that requires judgement and experience. Getting it wrong doesn’t cost you that much time these days, since the agent handles most of the planning work, but it does cost you your attention. When you ask the agent to plan something trivial, you create decision points that demand your attention without being able to contribute taste or meaningful judgment. And when you skip planning for something complex, you lose the chance to verify assumptions before they get baked into code. Over time, this misallocation of attention compounds and makes it harder for you to balance implementation and exploration.
Technical debt is like a high-interest loan: it’s almost always better to pay it down continuously in small increments than to let it compound and tackle it in painful bursts. Human taste is captured once, then enforced continuously on every line of code. This also lets us catch and resolve bad patterns on a daily basis, rather than letting them spread in the codebase for days or weeks.
Harness engineering: leveraging Codex in an agent-first world By Ryan Lopopolo, OpenAI
Even when you think you’ve found the right balance for a task, the agent will still uncover ambiguities that you didn’t anticipate. Your workflow has to allow for that, so that new decision points can surface naturally rather than assuming everything was settled when the agent started building. For example, when I was building a mind map app, I wanted automated graph layout and chose the dagre library. It’s a well-known layout library and the agent didn’t raise any objections to my choice, but during implementation it ran into trouble with CommonJS imports in a ESM Next.js project. Its instinct was to pile on shims and workarounds, solving the problem at the implementation level where it encountered it. But the actual decision point was one level up, at the package choice itself, because the agent had defaulted to the old, unmaintained dagre package while the newer @dagrejs/dagre supports ESM natively and is actively maintained. Stopping to ask “are we even using the right package?” resolved the problem at the level where it originated and avoided overcomplicating the development of the remaining tasks.
Teaching Agents What to Escalate
Claude Code’s AskUserQuestion tool offers a useful model for how decision points work in practice. The AI encounters ambiguity, sends a specific question to the human, and continues once it has an answer. The reason this pattern works is that recognizing when a decision is needed is a much simpler problem than actually making the decision. An agent doesn’t need to know which path is best to notice that multiple valid paths exist and that the choice depends on context it doesn’t have. Matching the current tasks against a taxonomy of common decision points is something that agents can do reliably now, even when the underlying decisions require expert human judgment.
Figure-2: There are many different points in the workflow where the user’s input is needed to clarify the design, verify implementation choices, or choose which task to work on next. As the agent learns your preferences, some of these decisions can be automated.
Not every question that comes up between an idea and a plan actually needs your input. Some decisions have clear answers based on patterns you’ve already established, and letting the agent resolve those on its own means the questions that do reach you carry more weight. Once a plan has been broken into tasks, a new set of decision points emerges. Each task can be reviewed before implementation begins, giving you a chance to reorder priorities based on what you want to learn first, or catch assumptions that looked reasonable in the plan but don’t hold up once the implementation details have been filled in.
The more you pay attention to your own decision points, the more you notice that some of them come up again and again. For example, you find yourself consistently preferring ESM-compatible libraries, prototyping new features before writing tests, or wiring components together through streaming events instead of shared state. These recurring decisions naturally become a reusable library of design patterns that the agent can apply on its own, freeing your attention for the genuinely new decisions where your judgment matters precisely because there isn’t a pattern to fall back on yet. The agent’s job isn’t to have taste on your behalf, but to notice the moments where taste matters and put them in front of you.
Designing Workflows Around Judgment
As I got Claude Code running more tasks in parallel, I found that the hard part of agent-based development wasn’t the coding itself but knowing where my attention should go. The more agents I ran in parallel, the more ideas I could explore in parallel, but everything was spread across a bunch of different terminal sessions and a dozen different markdown files which I needed to keep track of in my head.
That’s what led me to build atelier.dev , an AI-native kanban board which grew out of my personal Claude Code development workflow. Rather than tracking progress through scattered files and terminal windows, tasks move through stages that help surface the moments where my input matters, so I get a single view of what’s running, what’s blocked on a decision, and what’s ready to verify. Each transition between column calls a custom agent skill to make sure that it’s operating at the correct level of abstraction.
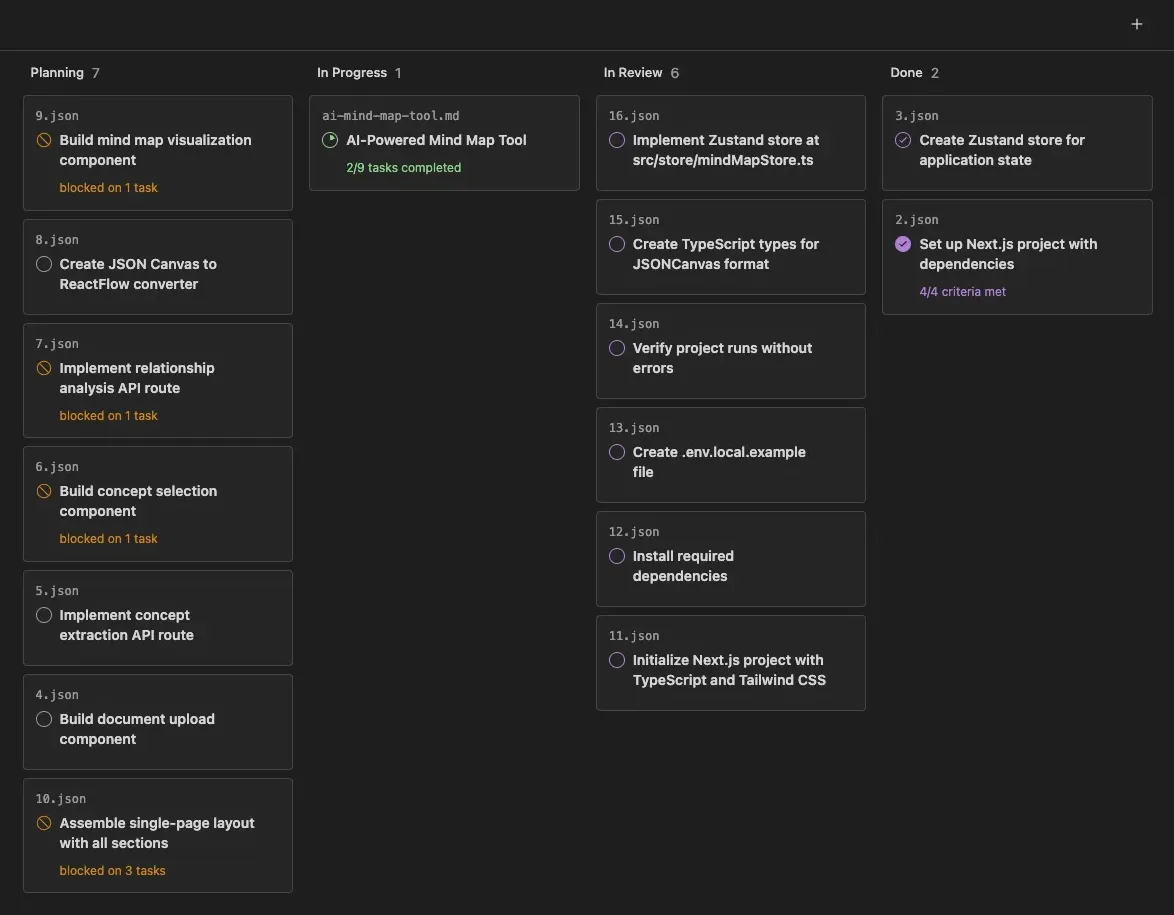
Figure-3: Atelier the user and the agent interact with tasks on the same kanban board. Every task is a file which the agent can read and write to. When the user drags a task to a new column it launches the agent with a custom agent skill to facilitate that transition.
Building Atelier helped me shift from thinking about verification of AI-written code to thinking about the cascade of decision points that produce it. Even when an AI agent appears to be fixing real problems, those problems exist within a frame created by earlier decisions which the same agent made. You often need to reframe a problem at a higher level to prevent this design debt from compounding.
Donella Meadows’ article “Leverage Points: Places to Intervene in a System” captures why this shift matters, ranking interventions by how much they actually change a system’s behavior. At the bottom are parameters, things like tweaking numbers within an existing structure. At the top are the rules of the system, the structure of information flows, and the mental models that drive everything else. Her key finding is that people overwhelmingly focus on parameter-level changes, which rarely changes how a system actually behaves.
See also: Leverage Points: Places to Intervene in a System by Donella Meadows
For example, code review catches real problems, things like style inconsistencies, error handling gaps, and design drift, but it operates mostly at the parameter level because the frame those problems exist within was already set by earlier design decisions. The review feels productive, and it is, but the decisions that had the most influence over what you’re reading happened before any code was written. Code quality still matters in agentic development, but it matters in the way that Meadows’ lower-leverage interventions matter: genuinely useful, but unable to alter the system’s overall direction on their own.
Figure-4: As we move from traditional development to centaur development to agent-based development, the decisions that actually require your judgment move upward toward design, workflow, and intent.
Decision points exist across the entire development cycle, from implementation details up through what to build, and in traditional development they’re spread more evenly. What changes as we move towards more agentic styles of development is where those decision points concentrate. As agents take on more of the implementation, debugging, and even planning of our system, the decisions that actually require your judgment move upward toward design, workflow, and intent, which means more of your attention is focused on the higher leverage design choices.
Meadows observed that higher-leverage interventions are counterintuitive. For example, handing quality controls like code review over to the agent feels short-sighted, but as Dex Horthy explained in his AI Engineer Summit talk, a mistake at the code level is one bad line, while a mistake at the specification level cascades into thousands of lines of the wrong code. This isn’t an argument against code review so much as an observation about where problems originate. Code review is good at catching the symptoms, but the conditions that produced them were set further upstream, and the further up the hierarchy your judgment operates, the more you’re catching those conditions before they compound into code built on the wrong foundation.
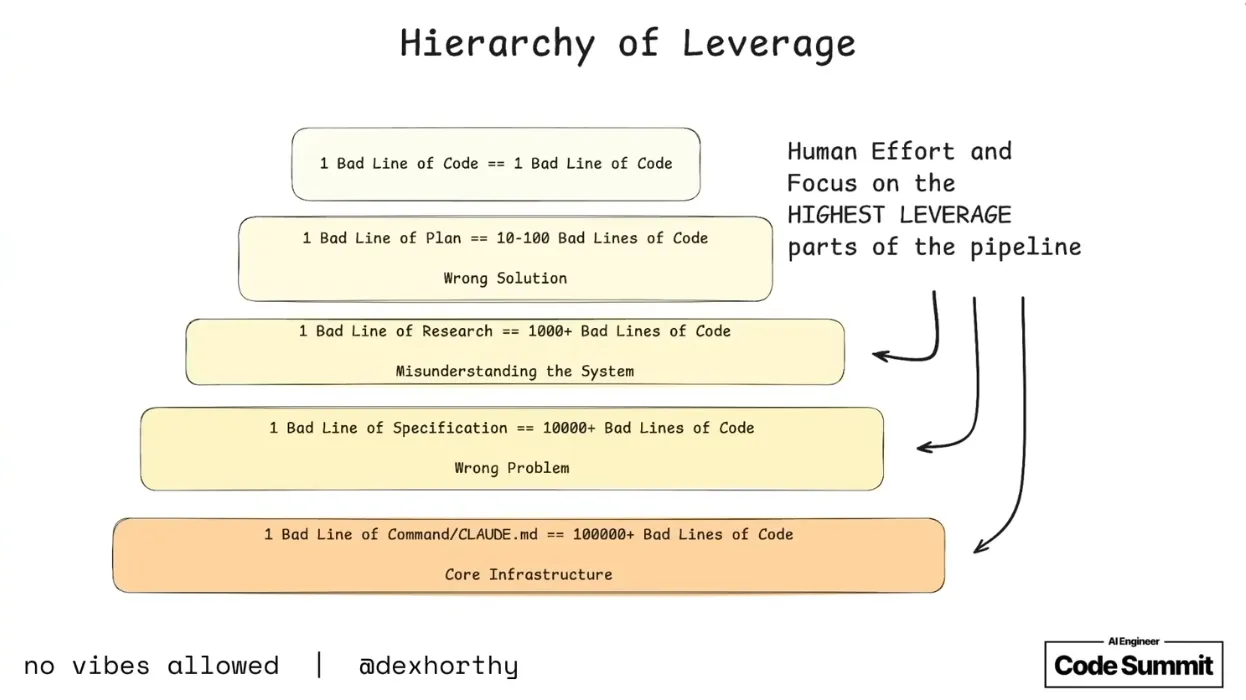
See also: No Vibes Allowed: Solving Hard Problems in Complex Codebases by Dex Horthy, HumanLayer
Designing your workflow around decision points means deliberately choosing which levels your judgment operates at. In practice, that means instead of reviewing every line of code, you’re choosing which parts of the application to add complexity to, enriching ideas through brainstorming, refining scope during planning, making architectural calls when the agent hits ambiguity, and verifying that each task is building towards your goal.
This is also where it helps to think about how you decompose larger projects into tasks. The natural instinct is to split up tasks by separation of concerns, building the database, the API, and the frontend in parallel tasks. But horizontal layers are hard to verify until all the layers are wired up, which creates verification debt that you have to pay off at the very end. Splitting a project into vertical slices, small features that cut through every layer and can each be independently run and checked, means each slice surfaces its own decision points. And the power of that parallel exploration is that it helps you discover which decisions actually matter early, before you’ve invested too much in any one direction.
Over time, we can expect models to get better and agents to take on more of their own orchestration, so you might wonder whether this level of supervision will become unnecessary, or whether all the decision points will eventually get automated away. But Meadows’ framework suggests the opposite. As AI handles more routine decisions on its own, the highest-leverage decision points actually become more valuable because the challenge of injecting taste and creative judgment into a workflow only grows as more of the execution becomes automated.
As AI handles more of the execution, our attention naturally shifts to decision design, how we structure our work so that the important choices are visible and the routine ones are handled. The question you should be asking of your own workflow is: where do you want your judgment to live? If you’ve tried agent-based development and went back to chat because you couldn’t trust the output, it’s worth trying again with a different focus. Reorient your workflow around finding the right decision points, and evaluate agent-based development on how well it surfaces the moments where your judgment matters instead of just looking at the final code it produces.